17. 09. 2024
Odkud carVertical čerpá svá data: jak se vytváří přehledy historie

Tadas Švenčionis

Klienti a obchodní partneři se nás často ptají: jak vznikají přehledy historie vozidel carVertical? Odkud pocházejí data?
Tyto dotazy dobře chápeme – přehledy historie vozidel mohou přinést skutečně až neuvěřitelné informace. Není to tak dávno, co se kupující aut museli spoléhat na poctivost prodejců a odbornost jejich mechaniků, aby si mohli koupit slušné ojeté auto.
No, i když bychom rádi měli kouzelnou moc, pravda je jednodušší a mnohem zajímavější. V tomto článku se podíváme na to, jak vznikají přehledy carVertical.
Bojíte se, že koupíte vrak?
Zkontrolujte jakýkoli VIN kód a odhalte historii vozidla!
VIN kód: klíč k odemknutí historie vozidla
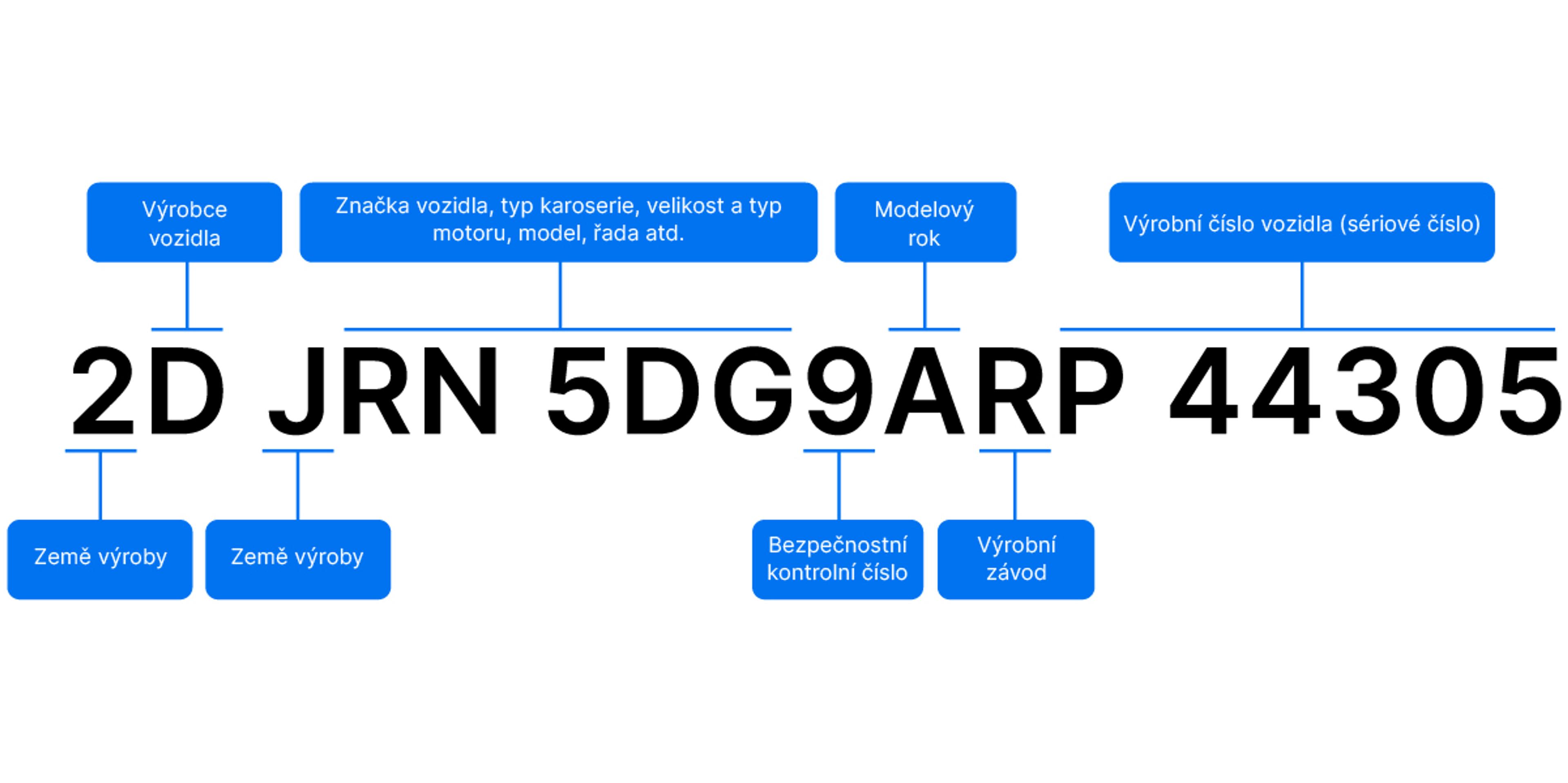
Většina přehledů carVertical začíná identifikačním kódem vozidla (VIN). Co tento kód představuje a jak nám může pomoci?
Téměř každé auto vyrobené po roce 1981 má jedinečný 17znakový kód VIN, který slouží jako otisk prstu vozidla. Různé instituce jako například policie, pojišťovny a servisy používají číslo VIN k zaznamenávání důležitých událostí v životě vozidla. Pomocí tohoto čísla se zaznamenávají nehody, krádeže, kontroly najetých kilometrů, změny vlastníků a mnoho dalšího.
Protože žijeme v digitální době, ukládá se většina těchto údajů do otevřených i soukromých databází. Klíčem k získání těchto údajů je právě VIN kód.
Jak vznikají přehledy carVertical: náhled do zákulisí

Zatímco přehled má být co nejsrozumitelnější, aby byl snadný k pochopení, technický proces, který za jeho vznikem stojí, je složitý, dynamický a neustále se vyvíjí. Níže se můžete podívat, jak pro vás měníme nezpracovaná data v jasné a využitelné poznatky.
1. Použití VIN kódu k vyhledávání dat

Po zadání VIN v aplikaci nebo na webových stránkách carVertical automaticky prohledá více než 900 zdrojů dat ve více než 40 zemích. To zahrnuje:
- pravní předpisy;
- národní policejní databáze;
- finanční instituce;
- národní či státní registry;
- inzerce;
- neziskové organizace.
2. Čištění dat a jejich třídění na použitelné části
Data, která získáváme z různých zdrojů, jsou obvykle nezpracovaná a vyžadují několik kroků zpracování. Uveďme si tento postup na příkladu:

Představte si, že se nám do rukou dostane švédský doklad na černý Mercedes-Benz GLC 300 s 5 000 skandinávskými mílemi (50 000 km) na tachometru, s datem 12. června 2021. Než budeme moci tuto informaci použít, musíme:
- Opravit případné chyby či nesrovnalosti. Data se do systémů často zadávají ručně, což vede k překlepům nebo jiným chybám.
- V případě potřeby údaje přeložit.
- Roztřídit informace do příslušných kategorií, např:
- Datum záznamu: 12. června 2021
- Země výroby: Švédsko
- Rok výroby: 2020
- Značka: Mercedes-Benz
- Model: Mercedes-Benz GLC 300
- Barva: černá
- Stav tachometru: 5 000
- Jednotka tachometru: skandinávské míle
Nyní můžeme tato data shromáždit s informacemi z ostatních nalezených záznamů a použít je k vytvoření přehledu.
3. Přiřazení roztříděných dat k příslušným sekcím přehledu
Abychom se mohli podívat blíže na to, jak se data zapracovávají do přehledu carVertical, ukážeme si tuto situaci na stejném černém Mercedesu z příkladu výše.
Z informací uvedených výše víme, že v době zaznamenávání informací, měl Mercedes na tachometru 50 000 km.
Důvodem, proč to „my“ (tedy systém carVertical) víme, je to, že jsme analyzovali dokument a vyčlenili tyto 3 informace – „Hodnota tachometru: 5 000“, „Jednotka tachometru: skandinávská míle,“ a „Datum záznamu: 12. června 2021“.
Nyní si představme, že jsme našli další 2 datové záznamy týkající se našeho Mercedesu, které nám nabízí následující informace:
- Dokument č. 1:
- Země záznamu: Švédsko
- Stav tachometru: 187 000 km
- Datum záznamu: 20. října 2022
- Dokument č. 2:
- Země záznamu: Finsko
- Datum technické kontroly: 7. září 2023
- Stav tachometru: 105,000 km
- Emise CO2: [x g/km]

Tyto informace vypovídají o mnohém – jen je musíme dát dohromady.
Za tímto účelem třídíme různé typy informací do jednotlivých sekcí přehledu. Například pokud máme 3 různé údaje o stavu tachometru a data jejich pořízení. Ty naleznete v sekci Tachometr v přehledu. Mezitím informace o technických prohlídkách najdete v sekcích Právní stav nebo Časová osa a dalších.
4. Používání statistických modelů k tvorbě poznatků a provádění oprav
Nyní tedy máme k dispozici data, která byla zpracována pro použití v přehledu carVertical. Ještě nás však čeká další práce „pod kapotou“ – především využití statistických modelů a dalších technologických řešení k odstranění problémů a obohacení našeho reportu.

Možností pro využití těchto technologií existuje příliš mnoho na to, abychom je mohli vyjmenovat, ale jako příklad můžeme uvést statistické modely, které uživatelům poskytují další informace (např. můžeme porovnat počet najetých kilometrů našeho ukázkového Mercedesu s jinými vozy stejného modelu, stáří a další).

Tento proces funguje oboustranně: používáme statistické modely k obohacení stávajícího přehledu a používáme údaje ze stejného přehledu k obohacení našich statistických modelů.
5. Vytvoření přehledu
V tomto okamžiku se přesuneme k vygenerování přehledu carVertical, který obohatíme o všechny shromážděné, vyčištěné, roztříděné a zpracované informace. Pojďme nyní ještě naposledy využít náš ukázkový Mercedes. Níže uvádíme, jak by mohla vypadat jeho sekce Tachometr s počtem najetých kilometrů:

I když se tento černý Mercedes může zdát jako lákavá koupě, výše uvedený graf by měl každého potenciálního kupce přinutit se nad ním znovu zamyslet!
Uživatelé se mohou z přehledu také dozvědět o cestě vozu, který dorazil do Švédska, byl prodán jinému majiteli ve Švédsku a nakonec skončil ve Finsku. Pomocí statistických modelů můžeme také poskytnout cenové rozpětí pro tento model vozu, stejně jako graf průměrného počtu najetých kilometrů (i když ten by se s ohledem na stočení najetých kilometrů příliš nezměnil!) a mnohem více.
Zkontrolujte svůj VIN kód
Prověřením historie vozidla předejdete nákladným problémům. Pořiďte si přehled ihned!
Poškození, najeté kilometry a vše ostatní: které údaje pocházejí z jakých zdrojů?
Aniž bychom se v našich přehledech zabývali konkrétními databázemi či zdroji konkrétních informací, můžeme se podívat na některá obecná pravidla, odkud mohou určité typy dat pocházet.
Než to však uděláme, je důležité si uvědomit několik věcí:
- Stejný typ informací může pocházet z různých typů zdrojů. Např. záznamy o najetých kilometrech (i stejný záznam) mohou pocházet z návštěvy servisu, policejního záznamu nebo odjinud.
- V jednotlivých zemích existuje mnoho různých informací. Stejné typy institucí mohou mít v systémech různé role pro vedení záznamů v závislosti na dané zemi.
Takže kde můžete najít záznamy o poškození, záznamy z tachometru nebo další informace?

carVertical is ISO/IEC 27001:2017 cecarVertical je držitelem certifikátu ISO/IEC 27001:2017
Jako společnost, která se zabývá zpracováním velkého množství dat, bereme bezpečnost velmi vážně. Na důkaz našeho závazku získala společnost carVertical certifikaci ISO/IEC 27001:2017 – celosvětový standard pro bezpečnost informací.
Co to znamená? Aby společnost mohla získat certifikaci ISO/IEC 27001:2017, musí zavést nástroje a postupy, které chrání všechny ústní, písemné a elektronické informace, a to jak přijaté, tak odeslané, vytvořené, spravované a používané před všemi možnými hrozbami: vnějšími, vnitřními, úmyslnými nebo náhodnými.
Tento certifikát zaručuje, že jsme zavedli přísná opatření na ochranu všech ústních, písemných a elektronických informací před všemi hrozbami – ať už vnějšími, vnitřními, náhodnými nebo úmyslnými.
Co to znamená pro vás? Vaše osobní údaje, údaje z přehledů a finanční údaje jsou chráněny špičkovými bezpečnostními systémy. Chcete další podrobnosti? Podívejte se na naše zásady bezpečnosti informací a systém řízení bezpečnosti informací (ISMS).
Seznamte se s datovým týmem carVertical!

Přehled carVertical je přehledný a srozumitelný, ale za touto jednoduchostí stojí spousta věcí. Dobře to odráží naše datové oddělení: carVertical má v současnosti téměř 200 zaměstnanců a až 15 % z nich pracuje na zpracování dat.
Ti, kteří jsou dobří v matematice, vědí, že se jedná o značný počet lidí!
Oddělení má čtyři specializované týmy:
- Tým pro získávání dat se zaměřuje na shromažďování nezpracovaných dat.
- Tým datového inženýrství je zodpovědný za budování a údržbu naší datové infrastruktury a potrubí.
- Oddělení strojového učení vyvíjí a nasazuje modely založené na strojovém učení.
- Tým zabývající se analýzou dat vyhodnocuje data s cílem získat poznatky a informovat o obchodních rozhodnutích.
Každý z těchto týmů hraje klíčovou roli při vytváření přehledu carVertical – bez nich bychom doslova nemohli existovat!
FAQ (Často kladené dotazy)
Autor článku:
Tadas Švenčionis
Tadas je šéfredaktorem blogu carVertical. Jako fanoušek všech automobilových a moderních technologií se snaží složitá témata podat jednoduše a zábavně - koneckonců, k čemu je dobrý příběh, kterému nikdo nerozumí? Tadas tráví volné dny čtením, hraním her a tím, že do litevského Vilniusu přináší hudbu, o kterou se nikdo neprosil.