11/10/2024
Sources des données de carVertical : comment les rapports d’historique sont créés

Tadas Švenčionis

Nos clients et nos partenaires commerciaux nous posent souvent la question suivante : comment les rapports sur l'historique des véhicules de carVertical sont-ils créés ? D'où proviennent les données ?
Ces questions sont compréhensibles : les rapports sur l'historique des véhicules peuvent révéler des informations vraiment inattendues. Il n'y a encore pas si longtemps, les acheteurs de voitures devaient se fier à l'honnêteté des vendeurs et à l'expertise de leur mécanicien pour obtenir une voiture d'occasion décente.
Même si nous aimerions avoir des pouvoirs magiques, la vérité est en fait plus simple… et plus intéressante. Dans cet article, nous allons t’expliquer comment sont créés les rapports carVertical.
Tu as peur d'acheter une épave ?
Vérifie n'importe quel VIN pour connaître l'historique d'un véhicule !
Le VIN : la clé pour débloquer l’historique de ton véhicule
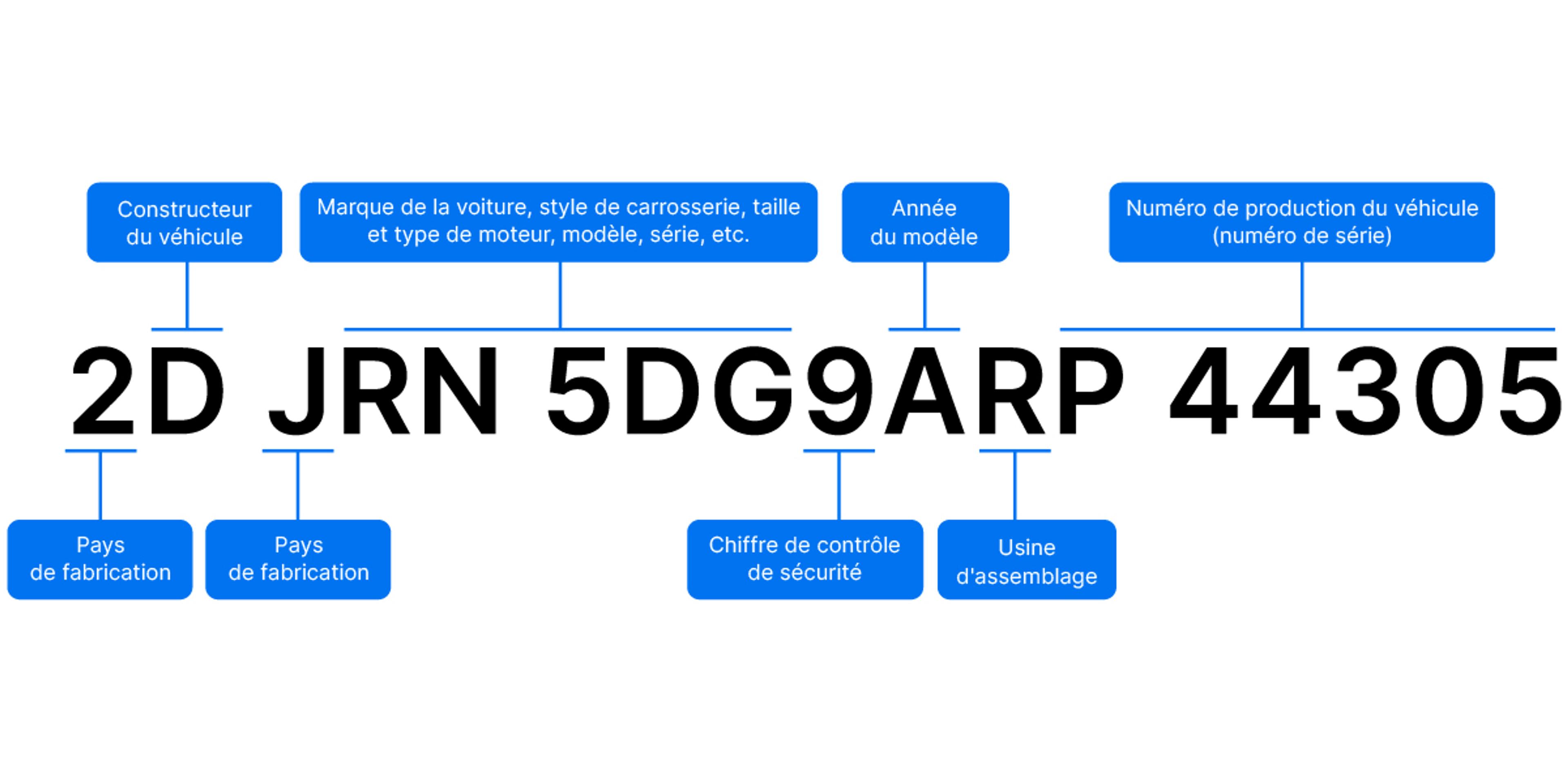
La plupart des rapports carVertical commencent avec le numéro d'identification du véhicule (VIN). Qu'est-ce que c'est et comment cela nous aide-t-il ?
Presque toutes les voitures fabriquées après 1981 ont un numéro d'identification unique de 17 caractères, qui constitue l'empreinte digitale du véhicule. Ce VIN (de l’anglais Vehicle Identification Number, soit Numéro d’Identification du Véhicule) est utilisé par diverses institutions - comme la police, les compagnies d'assurance et les centres d'entretien - pour enregistrer les principaux événements de la vie d'une voiture. Les accidents, les vols, les relevés kilométriques, les changements de propriétaire et bien d'autres choses encore sont enregistrés par l’intermédiaire de ce numéro.
Comme nous vivons à l'ère du numérique, la plupart de ces données sont stockées dans des bases de données ouvertes ou privées. Le VIN est la clé qui nous permet d'accéder à ces données.
Comment les rapports carVertical sont créés : jetons un oeil en coulisses

Si le rapport est simple et facile à comprendre, le processus technique qui le sous-tend est complexe, dynamique et en constante évolution. Voici un aperçu de la manière dont nous transformons ces données brutes en informations claires et exploitables.
1. Utilisation du VIN pour rechercher des données

Quand tu saisis un VIN sur l'application ou le site web carVertical, nous effectuons automatiquement une recherche parmi plus de 900 sources de données réparties dans plus de 40 pays. Elles incluent :
- Les autorités
- Les bases de données des polices nationales
- Des institutions financières
- Les registres nationaux / d'État
- Les petites annonces
- Des organisations à but non lucratif
2. Nettoyage des données et tri en segments exploitables
Les données que nous recevons de diverses sources sont généralement brutes et nécessitent plusieurs étapes de traitement. Prenons un exemple pour illustrer cette procédure :

Imaginons que nous recevions un document suédois pour une Mercedes-Benz GLC 300 noire avec 5 000 milles scandinaves (50 000 km) au compteur, daté du 12 juin 2021. Avant de pouvoir utiliser cette information, nous devons :
- Corriger les erreurs et les incohérences. Les données sont souvent saisies manuellement dans les systèmes, ce qui entraîne des fautes de frappe ou d'autres erreurs.
- Traduire les données, si nécessaire.
- Classer les informations dans des catégories pertinentes, telles que :
- Date du relevé : 12 juin 2021
- Pays : Suède
- Année de fabrication : 2020
- Marque : Mercedes-Benz
- Modèle : GLC 300
- Couleur : Noire
- Valeur du compteur kilométrique : 5 000
- Unité du compteur kilométrique : Milles scandinaves
Nous pouvons maintenant regrouper ces données avec des informations provenant d'autres enregistrements trouvés et les utiliser pour générer le rapport.
3. Affectation des données triées aux sections pertinentes du rapport
Pour mieux comprendre comment les données sont intégrées dans le rapport carVertical, prenons la même Mercedes noire.
Nous savons, d'après le document ci-dessus, que le compteur kilométrique affichait 50 000 km au moment où ces informations ont été enregistrées.
La raison pour laquelle « nous » (c'est-à-dire le système carVertical) le savons est que nous avons analysé le document et isolé ces trois éléments d'information : « Valeur du compteur kilométrique : 5 000 », « Unité du compteur kilométrique : milles scandinaves » et « date d'enregistrement : 12 juin 2021 ».
Imaginons maintenant que nous ayons trouvé deux autres enregistrements de données sur cette Mercedes, offrant les informations suivantes :
- Document n° 1 :
- Pays d'enregistrement : Suède
- Kilométrage : 187 000 km
- Date d'enregistrement : 20 octobre 2022
- Document n° 2 :
- Pays d'enregistrement : Finlande
- Date du contrôle technique : 7 septembre 2023
- Kilométrage : 105 000 km
- Émissions de CO2 : [x g/km]

Ces informations racontent toute une histoire, il suffit de les rassembler.
Pour ce faire, nous regroupons les types d'informations dans nos sections de rapport. Par exemple, nous avons trois relevés de compteur kilométrique et les dates auxquelles ils ont été effectués. Ces données apparaîtront dans la section Kilométrage du rapport. Les informations relatives au contrôle technique se trouveront quant à elles dans les sections Statut juridique et Chronologie, etc.
4. Utilisation de modèles statistiques pour générer des informations et effectuer des corrections
Nous disposons donc des données et elles ont été traitées pour être utilisées dans un rapport carVertical. Mais il reste encore du travail « sous le capot », principalement en utilisant des modèles statistiques et d'autres solutions technologiques pour résoudre les problèmes et enrichir le rapport.

Les possibilités d’utilisation de ces technologies sont trop nombreuses pour être toutes citées, mais à titre d'exemple, nous utilisons des modèles statistiques pour fournir des informations supplémentaires aux utilisateurs (par exemple, nous pouvons comparer le kilométrage de notre Mercedes avec celui d'autres voitures du même modèle, du même âge, etc.)

Ce processus fonctionne dans les deux sens : nous utilisons des modèles statistiques pour enrichir le rapport actuel et nous utilisons les données du rapport actuel pour enrichir nos modèles statistiques.
5. Création du rapport
À ce stade, toutes les informations que nous avons recueillies, nettoyées, triées et enrichies sont utilisées pour générer un rapport carVertical. Revenons à notre Mercedes pour un dernier exemple. Voici à quoi pourrait ressembler sa section Kilométrage :

Si cette Mercedes noire peut sembler attrayante, le graphique ci-dessus devrait faire réfléchir tout acheteur potentiel !
Le rapport fournit également des informations sur le parcours de la voiture : arrivée en Suède, vente à un autre propriétaire toujours en Suède et enfin arrivée en Finlande. En utilisant des modèles statistiques, nous pouvons également fournir la fourchette de prix pour ce modèle de voiture, ainsi qu'un graphique du kilométrage moyen (bien que ce dernier n’évoluera pas beaucoup, compte tenu de la manipulation du kilométrage), et plus encore.
Vérifie ton VIN
Évite les problèmes coûteux en vérfiant l'historique d'un véhicule. Obtiens un rapport instantanément !
Dommages, relevés kilométriques et tout le reste : quelles données proviennent de quelles sources ?
Sans aborder les bases de données spécifiques ou les sources d'informations spécifiques dans nos rapports, nous pouvons aborder certaines règles générales concernant l'origine de certains types de données.
Mais avant cela, il est important de comprendre certaines choses :
- Le même type d'information peut provenir de différents types de sources. Par exemple, les relevés de kilométrage (même le même relevé) peuvent provenir d'une visite d'entretien, d'un dossier de police ou d'une autre source.
- Il y a une grande diversité d'un pays à l'autre. Les mêmes types d'institutions peuvent avoir des rôles différents en matière d'archivage dans les systèmes, selon le pays.
Alors où peux-tu trouver ces relevés de dommages, ces relevés de compteur kilométrique et autres informations ?

carVertical a reçu la certification ISO/IEC 27001:2017
En tant qu'entreprise traitant de nombreuses données, nous prenons la sécurité très au sérieux. Pour prouver notre engagement, carVertical a obtenu la certification ISO/IEC 27001:2017 - la norme mondiale en matière de sécurité de l'information.
Qu'est-ce que cela signifie ?
Pour obtenir la certification ISO/IEC 27001:2017, une entreprise doit mettre en œuvre des outils et des procédures protégeant toutes les informations verbales, écrites et électroniques reçues, envoyées, créées, gérées et utilisées contre toutes les menaces possibles : externes, internes, intentionnelles ou accidentelles.
Cette certification signifie que nous avons en effet mis en place des mesures strictes pour protéger toutes les informations verbales, écrites et électroniques contre toutes les menaces, qu'elles soient externes, internes, accidentelles ou intentionnelles.
Qu'est-ce que cela signifie pour toi ? Tes données personnelles, les données de tes rapport et tes données financières sont toutes protégées par des systèmes de sécurité de premier plan. Tu veux en savoir plus ? Consulte notre politique de sécurité de l'information et notre système de gestion de la sécurité de l'information (SGSI).
Rencontre l'équipe data de carVertical !

Le rapport de carVertical est simple et facile à lire, mais il y a beaucoup de choses qui entrent en jeu derrière cette simplicité. Notre département data en est un bon reflet : carVertical compte actuellement près de 200 employés, dont 15 % travaillent sur les données.
Ça représente un nombre important de personnes douées en maths !
Le département compte 4 équipes spécialisées :
- L'acquisition de données se concentre sur la collecte de données brutes
- L'ingénierie des données est responsable de la construction et de la maintenance de notre infrastructure de données et de nos pipelines.
- L'ingénierie de l'apprentissage automatique (Machine Learning Engineering) développe et déploie des modèles d'apprentissage automatique.
- Les analystes de données analysent les données pour en extraire des informations et éclairer les décisions de l'entreprise.
Chacune de ces équipes joue un rôle crucial dans l'élaboration du rapport carVertical - sans elles, nous n'existerions pas !
Questions fréquemment posées
Articles par
Tadas Švenčionis
Tadas est le rédacteur en chef du blog carVertical. Fan de tout ce qui touche à l'automobile et la technologie, il met un point d'honneur à rendre les sujets complexes simples et attrayants – après tout, à quoi sert une histoire que personne ne comprend ? Tadas passe son temps libre à lire, à jouer aux jeux-vidéos et à apporter à Vilnius, en Lituanie, de la musique que personne n'a demandée.