15/12/2021
WMI Suggest: learning by trial and error with the help of AI

Tadas Švenčionis

The success of carVertical as a company depends on accurate Vehicle Identification Numbers (VINs). Allow us to explain.
Our VIN decoder is a powerful tool that can tell customers about any motor vehicle in the world. Accident history, records of odometer fraud and theft – all that information can be yours, assuming you have the VIN exactly as it appears on the vehicle.
Unfortunately, people aren’t perfect, and in the past, a single typo could spoil everything. Not anymore!
With the help of an AI-based-recommendation engine we developed, our basic VIN decoder is evolving into an advanced vehicle history check. This latest improvement allows us to handle mistakes in the WMI part of the VIN – the first 3 digits, which seem to be the most difficult for customers to get correctly.
This cool piece of technology brings us one step closer to our goal – bringing transparency on the used car market to a new level.
So, how did we do it, why did we do it, and what exactly did we do?

Looks can be deceiving!
Don't risk your safety - check it with carVertical first
Why are we improving our VIN decoder?
Most cars and motorcycles in the world, independent of their type and model, have a VIN. This code doesn’t just serve as a unique identifier. In fact, having a VIN often means you can get all sorts of information about the vehicle – from manufacturer information to a detailed vehicle history.
VIN consists of 17-digits, which can sometimes be broken down into three parts indicating: country and manufacturer, general characteristics, and details of the specific car. At this point, we have focused on the first part, which is also known as the WMI:
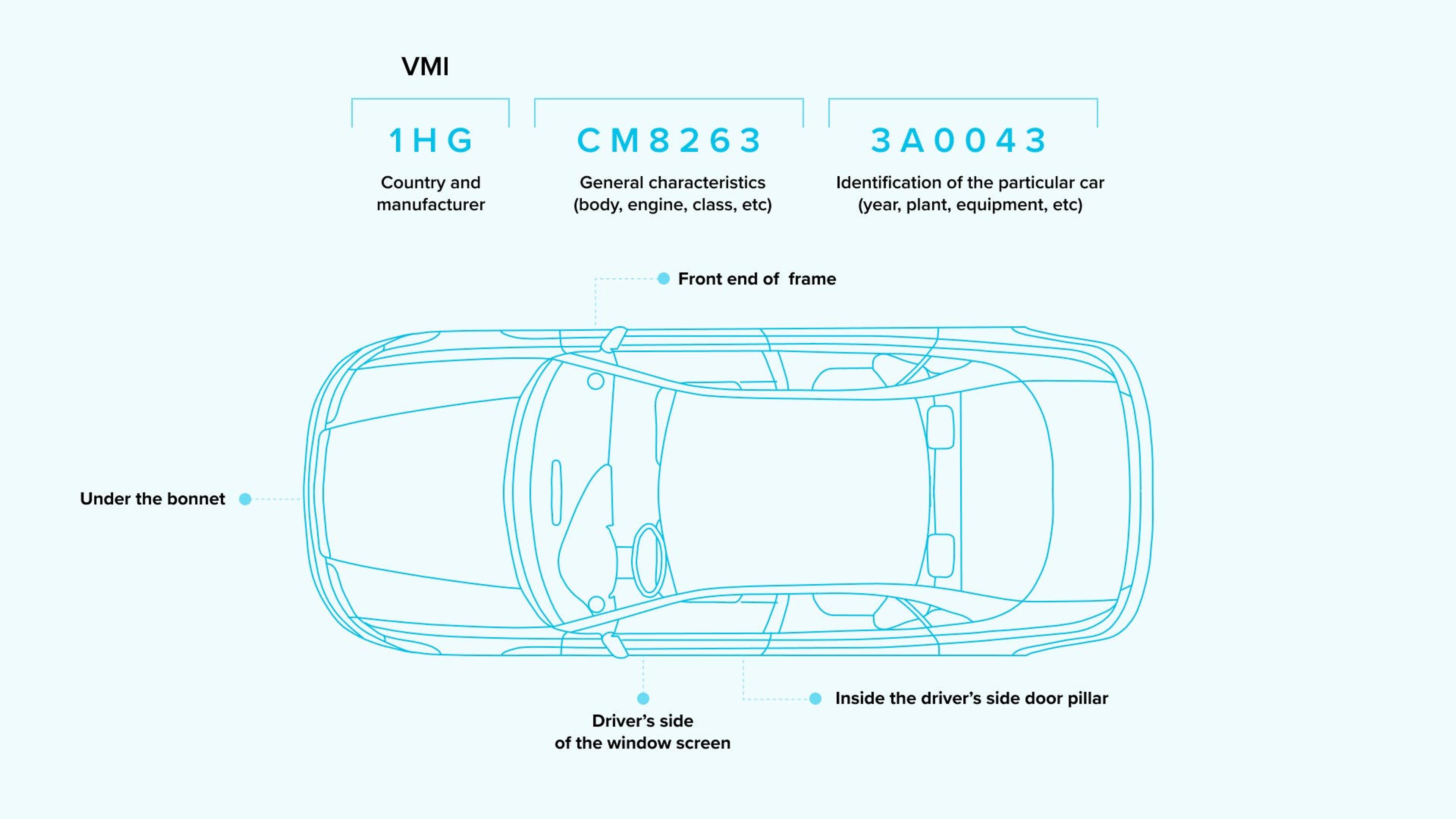
Yet for all its utility, the VIN is a complicated code, and one that’s easy to misread or write down incorrectly. And unfortunately, for us to retrieve information using the VIN, all of the digits in the code have to be correct.
This causes many problems!
As you can imagine, mistakes when entering the VIN into our decoder tool are quite frequent. And it’s no surprise – mistaking WVW for WWW or VVV can be very easy. If this happens, we can’t provide a vehicle history report.
Originally, to help our customers with incorrectly-entered or invalid VINs, we had a system that relied on a list of supported WMIs. This caused us to reject any unsupported WMIs as invalid, annoying the customer and lowering our sales.
Essentially, this was a terrible (and very expensive!) gatekeeping mechanism. You see, upon close inspection, we found that gatekeeping mechanism denials accounted for around 4% of all VIN check attempts on our system.
Instead of simply returning an error of ’Bad VIN - Check it again’ and losing out on earnings, we decided to look for a different way. And after some tinkering, our engineers came up with an innovative and, we think, pretty awesome, solution!
Solution: getting more accurate VINs through machine learning
Our solution is built around a classification model with a twist. We understood that, instead of simply checking whether the WMI value in the VIN was correct, we could suggest our customers try one of a number of similar, valid WMI combinations.
Due to the nuances of the VIN structure, we can’t fix all typos made by customers. However, our solution works for the WMI because this part of the VIN is always unique to the manufacturer and the assembly line location.
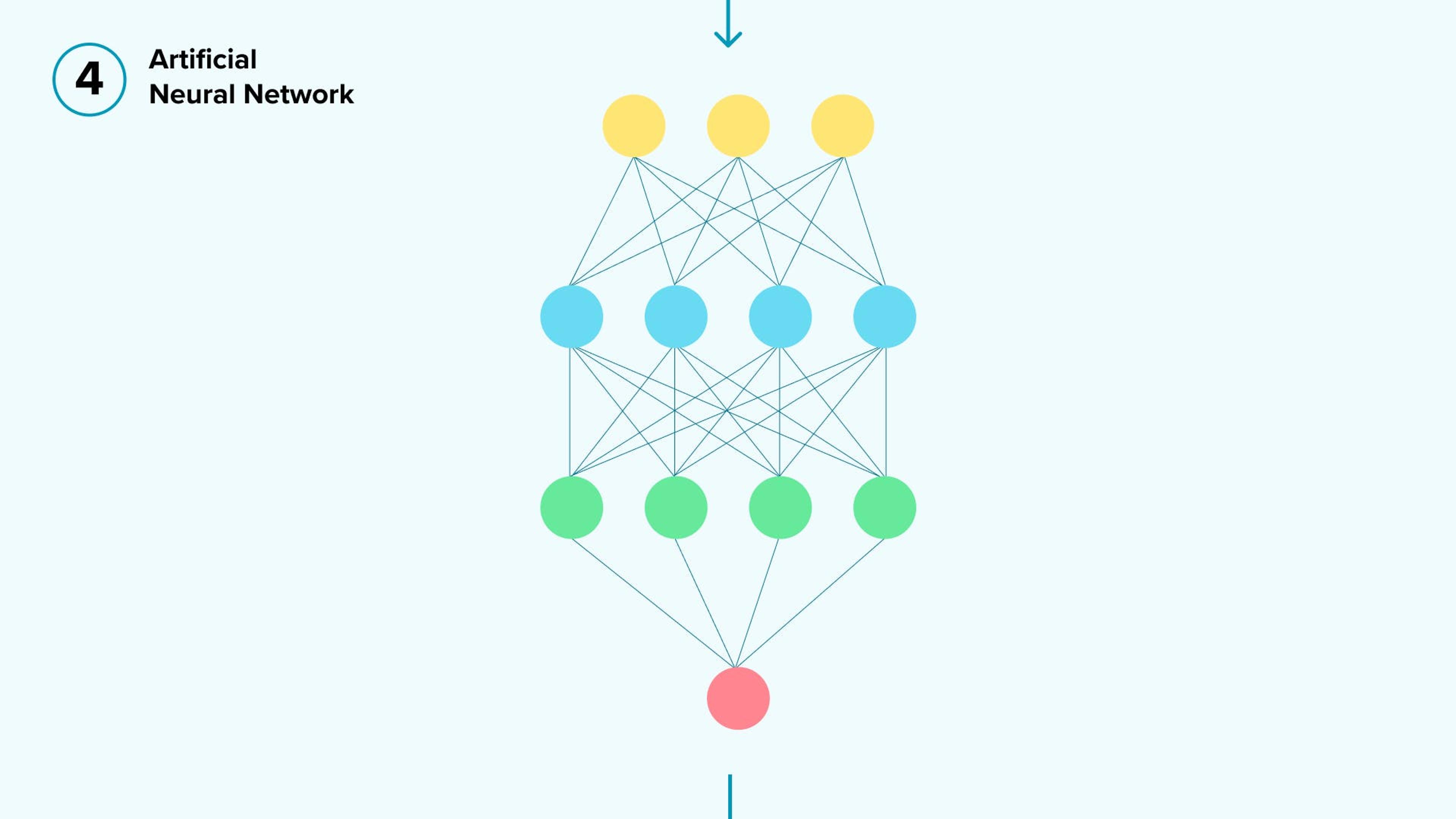
The model itself is based on artificial neural networks that are capable of finding patterns in the VIN. Here’s roughly how it works:
1.First, we break down the VIN into individual characters and assign a new vector representation of each symbol through an action called text embedding.
2.Then, we pass these values through multiple neural network layers to find hidden patterns between the WMI and the VIN structure.
To make it a bit harder for the model, we apply data augmentation to simulate possible mistypes. This helps generate additional data points, creates stronger bonds between the layers, and gives us a well-generalized model.
1.When the trained model gets a VIN with an incorrect WMI, it evaluates each VIN symbol. Thus, the probability we can suggest the correct WMI becomes quite high, even despite numerous mistypes from the customer.
2.The model output is used to construct new VIN suggestions for our clients, significantly improving the customer experience and increasing throughput.
Let’s dive a bit deeper. The WMI model is trained by applying these 6 steps:
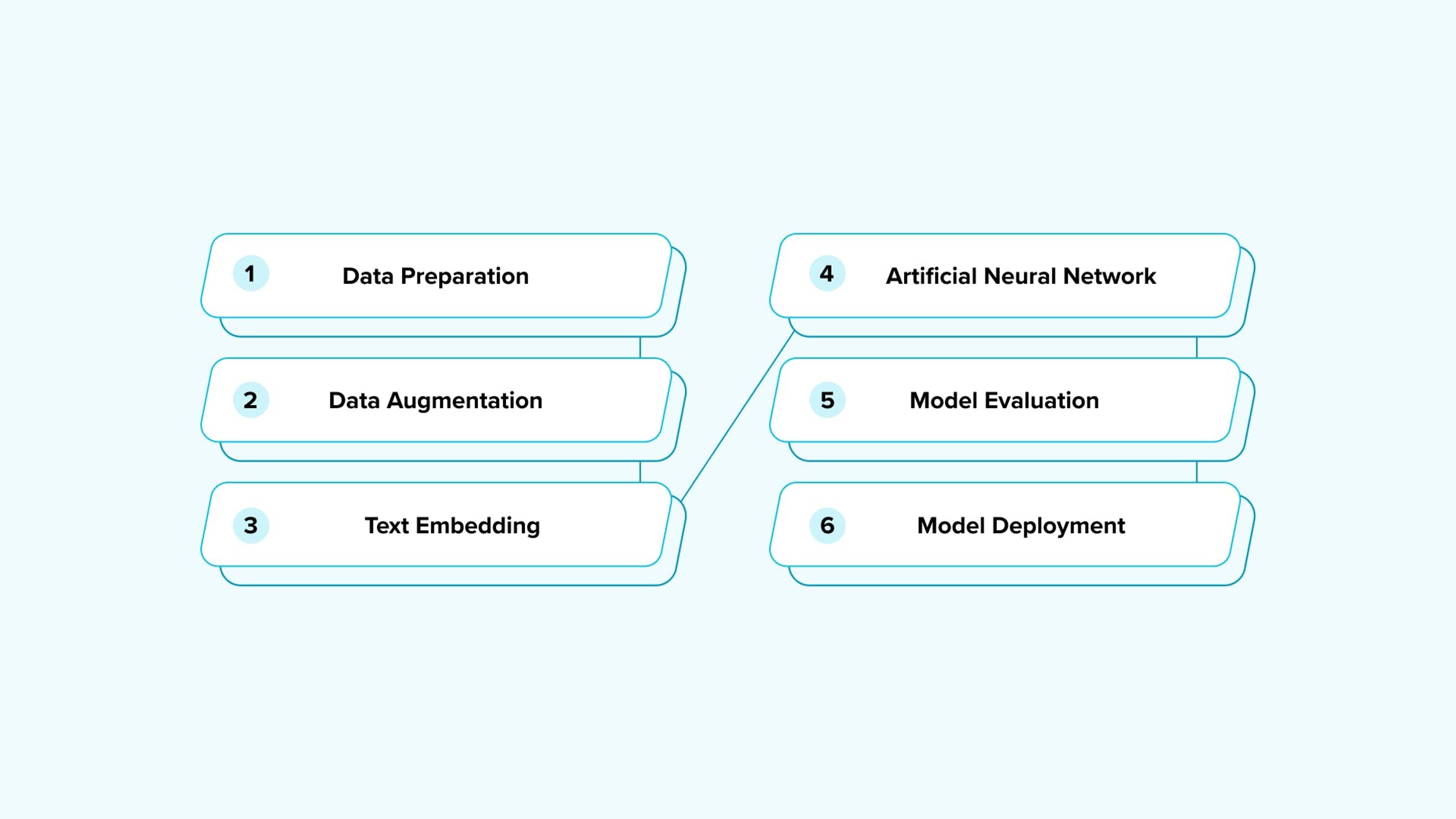
- Data Preparation: The WMI part is extracted from the input VIN.
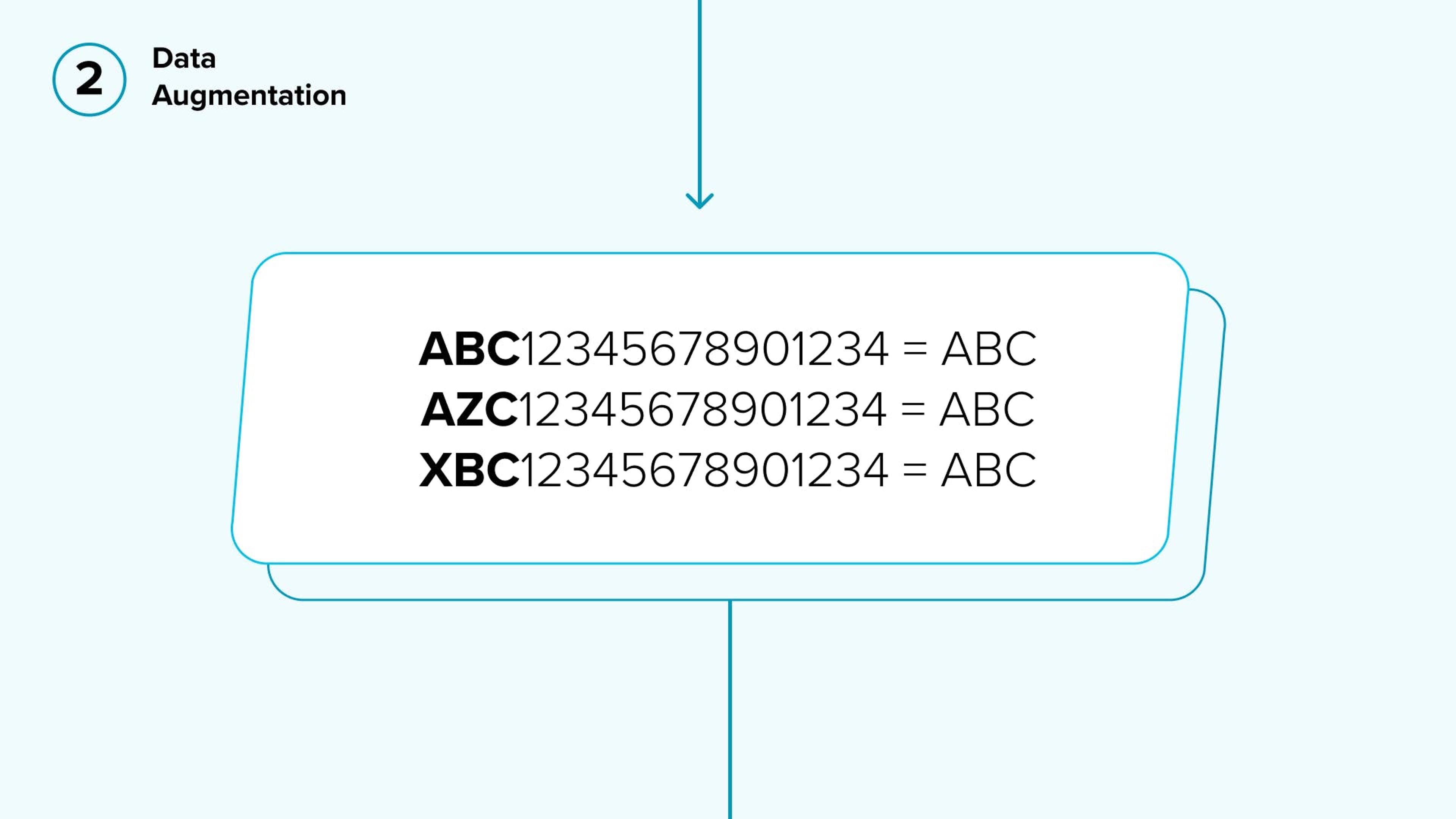
- Data Augmentation: Data augmentation is a technique to artificially create new training data from existing data to have a more robust model. In our case, we give the correct WMI part as the input, and offer additional possible variants.
In our current example, “ABC” is the correct WMI, whereas “AZC” and ”XBC” were randomly generated. The model works as long as at least one WMI symbol remains correct (both of our random examples have 2 correct symbols).
The purpose of this step is to simulate the sorts of mistakes people do in real life. By creating these “real” examples and adding more data, we are able to build a better model.
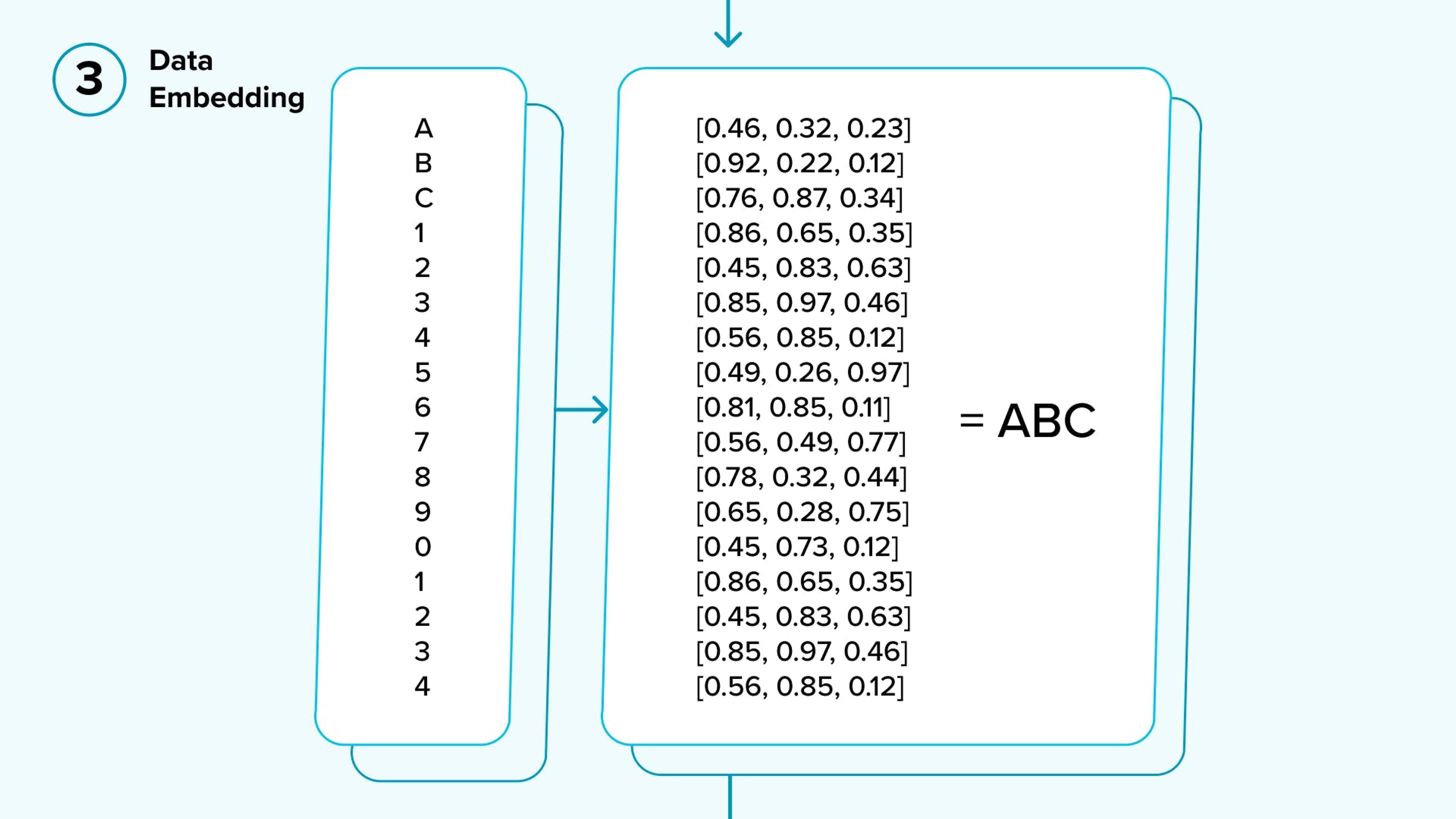
- Data Embedding: Computers can calculate, but they can’t read. Therefore, we have to turn the VIN into something that can be calculated. As you can see below, we do this by converting each symbol into vector notation.
Why vector notation and not an integer? Simply put, determining whether a VIN is correct requires complex calculations, which are impossible with one integer per symbol.
- Artificial Neural Network (ANN): The ANN searches for patterns within the VIN to help it determine the correct WMI. This is more complicated than it sounds: VINs are only standardized up to a point, and each car manufacturer has a certain level of flexibility in terms of what their VIN symbols actually represent. What does this mean?
Well, for example, the model may take a specific VIN and determine that, for this particular VIN, the WMI is best-determined by symbols 4 and 9. However, the pattern may be completely different for a different WMI.
Having performed all these calculations, the model determines which of the 500+ WMIs in existence are the most likely to be correct for the customer’s VIN.
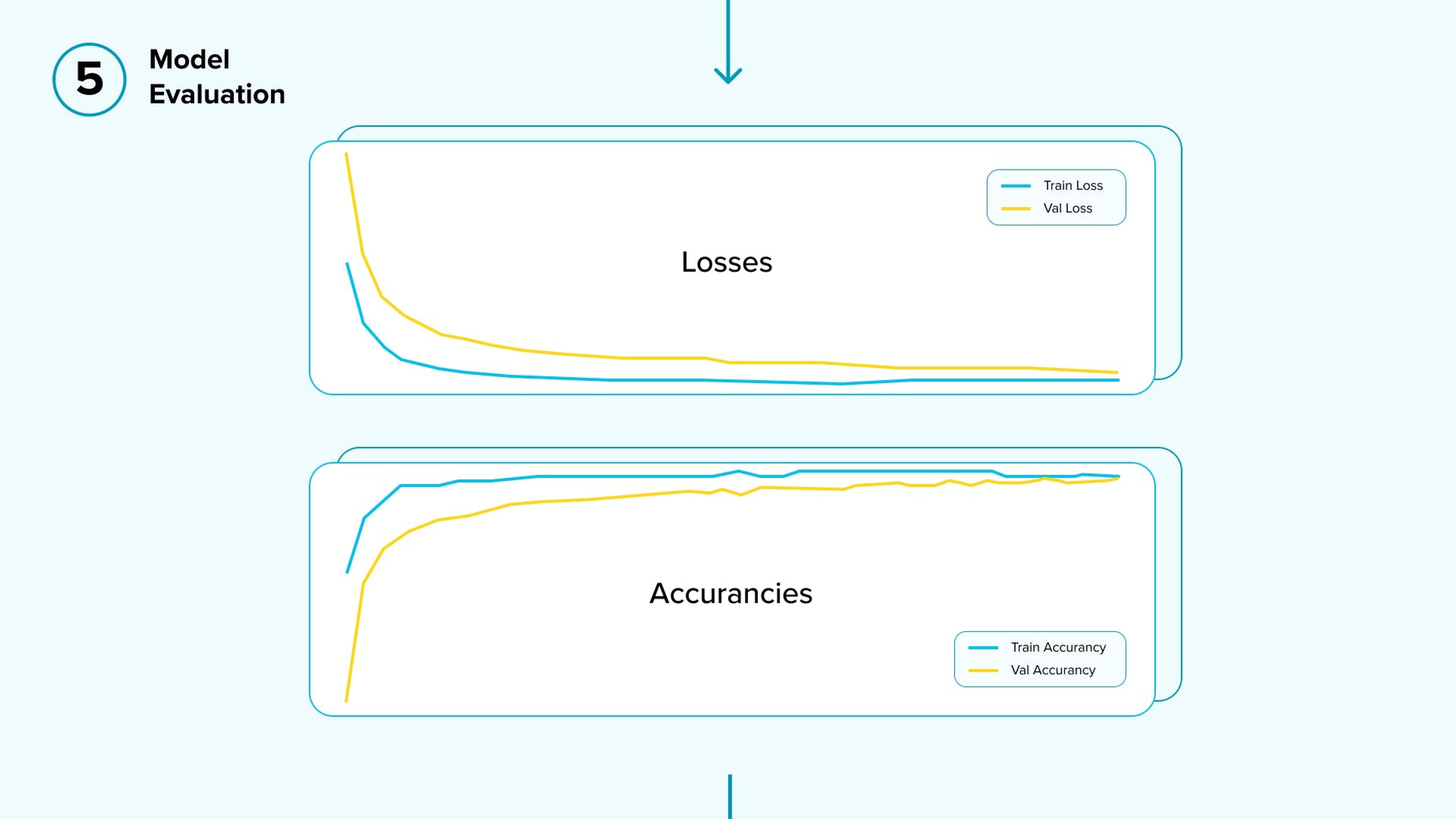
- Model Evaluation: You can see an example of the model’s output performance in the below graph. In short, the model has surprisingly good performance on both the training and validation dataset.
Also, it is clear that our team managed to achieve a generalized model that doesn’t suffer from either overfitting or underfitting, i.e., it doesn’t “know” too much (and is therefore capable of processing new information) and doesn’t “know” too little (enabling it to effectively detect patterns).
- Model Deployment: We deploy trained models to our system. When the model receives a bad input, it evaluates the WMI against all VIN symbols and suggests the most accurate match.

The feature isn’t only under testing but has already been implemented by both the front-end and back-end teams. Above is an example of the AI recommendation engine output. As you can see, if we misspell the WMI, the system gives us multiple suggestions to choose from.
What’s next?
In the near future, we will add an extra feature to check for WMIs that aren’t part of our database. For example, let’s imagine that a new car manufacturer enters the market with a new set of WMIs. The machine learning model will constantly retain and include new WMIs to deal with such a situation. In other terms, users will help us keep the WMI engine suggestions up to date.
Our integration of AI in the current VIN decoder offers a better user experience and puts it in a different place ahead of the current market solutions.
Luckily, the WMI suggestion engine is just one of the many ideas we have for improving our product. We’re always looking to learn new things and try new approaches.
With the help of our bright, tech-savvy team, we’re confident there will soon be no quarter left for scammers on the used car market!
If you think your ideas could make a difference and you would be a great fit for our team, don’t hesitate to check our Careers page!
Author: Audrius Kučinskas
Audrius is one of the co-founders and the Chief Technology Officer (CTO) of carVertical. As our tech visionary, he leads the drive towards innovation within the company. Audrius’ teams are responsible for product functionality and engineering solutions at carVertical.
Article by
Tadas Švenčionis
Tadas is the Editor in Chief of the carVertical Blog. A fan of all things automotive and tech, he makes a point of making complex topics simple and engaging – after all, what good is a story no one understands? Tadas spends his free days reading, gaming, and bringing music no one’s asked for to Vilnius, Lithuania.
