17.09.2024
Źródła danych carVertical: W jaki sposób tworzone są raporty historii

Tadas Švenčionis

Nasi klienci i partnerzy biznesowi często pytają nas, w jaki sposób tworzone są raporty historii pojazdów carVertical? Skąd pochodzą dane?
Takie pytania są oczywiście zrozumiałe – raporty na temat historii pojazdu mogą zawierać naprawdę nieoczekiwane informacje. Jeszcze nie tak dawno, gdy nabywcy samochodów chcieli kupić przyzwoity używany samochód, musieli polegać na uczciwości sprzedawców i wiedzy ich mechaników.
Cóż, chcielibyśmy mieć magiczne moce, ale prawda, choć nadal interesująca, jest jednak prozaiczna. W tym artykule wyjaśnimy, w jaki sposób tworzone są raporty carVertical.
Obawiasz się zakupu złomu?
Sprawdź numer VIN i poznaj historię pojazdu!
Numer VIN: klucz do odblokowania historii pojazdu
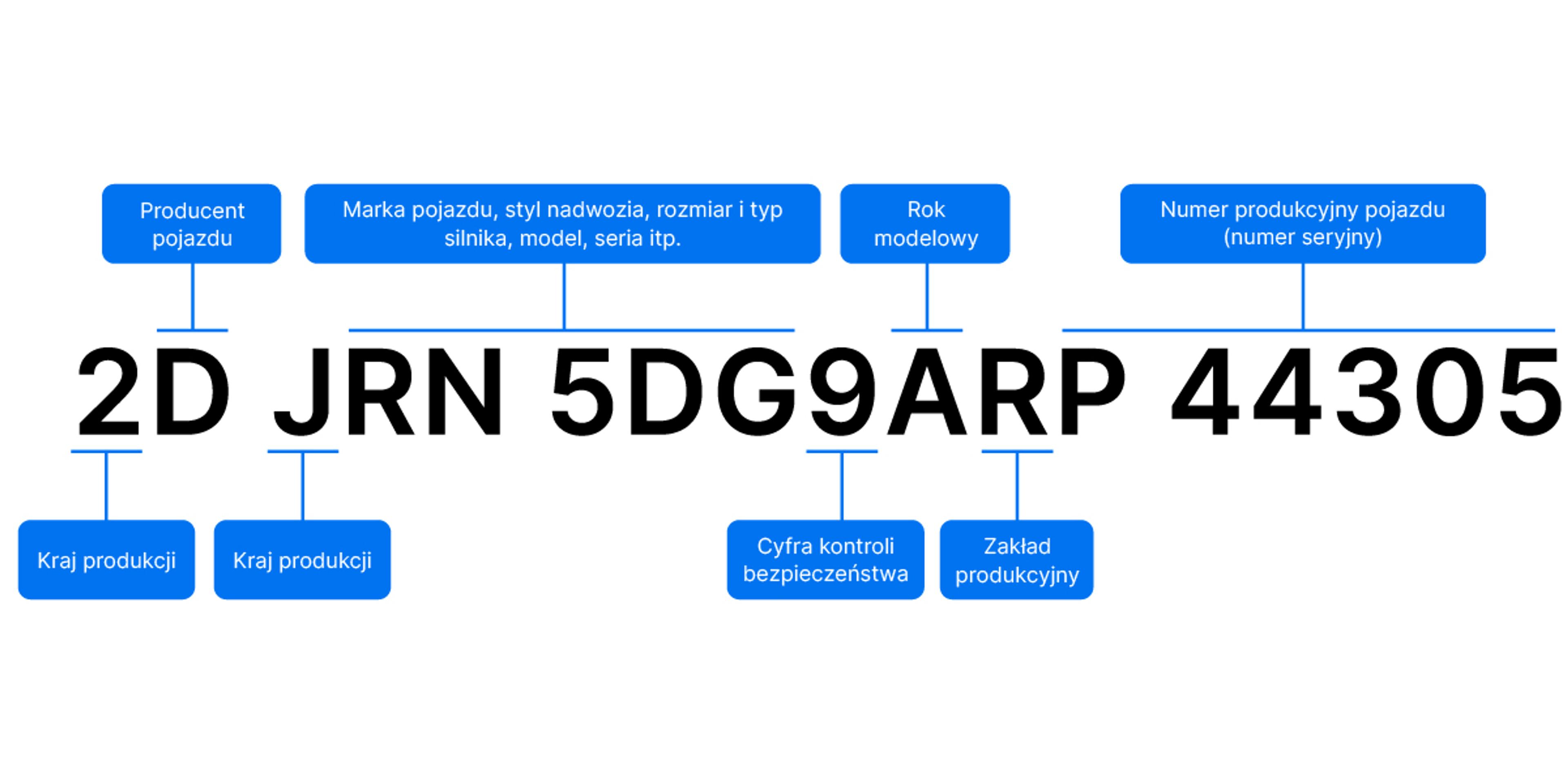
Większość raportów carVertical zaczyna się od numeru identyfikacyjnego pojazdu (VIN). Czym jest VIN i w jaki sposób może nam pomóc?
Prawie każdy samochód wyprodukowany po 1981 roku ma unikatowy 17-znakowy numer VIN, który działa jak odcisk palca pojazdu. Numer VIN jest wykorzystywany przez różne instytucje – jak policja, firmy ubezpieczeniowe i centra serwisowe – do rejestrowania najważniejszych wydarzeń z życia samochodu. Wypadki, kradzieże, kontrole przebiegu, zmiany właściciela i wiele innych zdarzeń jest rejestrowanych za pomocą tego numeru.
Ponieważ żyjemy w erze cyfrowej, większość tych danych jest przechowywana w otwartych i prywatnych bazach danych. Numer VIN jest naszym kluczem do uzyskania tych danych.
Jak tworzone są raporty carVertical: zaglądamy za kulisy

Podczas gdy raport sam w sobie jest bardzo czytelny i łatwy w odbiorze, stojący za nim proces techniczny jest złożony, dynamiczny i stale ewoluuje. Poniżej przedstawiamy, w jaki sposób przekształcamy surowe dane w jasne i przydatne informacje.
1. Używanie numeru VIN do wyszukiwania danych

Po wpisaniu numeru VIN w aplikacji lub na stronie internetowej carVertical, automatycznie przeszukujemy ponad 900 źródeł danych w ponad 40 krajach. Obejmuje to:
- Organy ścigania
- Krajowe policyjne bazy danych
- Instytucje finansowe
- Rejestry krajowe / stanowe
- Ogłoszenia drobne
- Organizacje non-profit
2. Czyszczenie danych i sortowanie ich na użyteczne części
Dane, które otrzymujemy z różnych źródeł, są zazwyczaj surowe i wymagają kilku etapów przetwarzania. Posłużymy się przykładem, aby zilustrować tę procedurę:

Wyobraźmy sobie, że otrzymujemy szwedzki dokument dotyczący czarnego Mercedesa GLC 300 z przebiegiem 5000 mil skandynawskich (50 000 km), datowany na 12 czerwca 2021 roku. Zanim będziemy mogli wykorzystać te informacje, musimy:
- Naprawić wszelkie błędy/niespójności. Dane są często ręcznie wpisywane do systemów, co prowadzi do literówek lub innych błędów.
- Przetłumaczyć dane, jeśli to konieczne.
- Posortować informacje według odpowiednich kategorii, takich jak:
- Data wpisu: 12 czerwca 2021 r.
- Kraj: Szwecja
- Rok produkcji: 2020
- Marka: Mercedes-Benz
- Model: GLC 300
- Kolor: czarny
- Przebieg: 5000
- Jednostka licznika kilometrów: Mile skandynawskie
Możemy teraz pogrupować te dane z informacjami z innych znalezionych wpisów i użyć ich do wygenerowania raportu.
3. Przypisywanie posortowanych fragmentów danych do odpowiednich sekcji raportu
Aby przyjrzeć się bliżej, w jaki sposób dane stają się częścią raportu carVertical, posłużmy się przykładem tego samego czarnego Mercedesa.
Z powyższego dokumentu wiemy, że w momencie rejestrowania tych informacji przebieg samochodu wynosił 50 000 km.
Powodem, dla którego „my” (czyli system carVertical) to wiemy, jest to, że przeanalizowaliśmy dokument i wyodrębniliśmy te 3 informacje – “Wartość przebiegu: 5000” “Jednostka licznika przebiegu: Mile skandynawskie” oraz “Data wpisu: 12 czerwca, 2021.”
Teraz wyobraźmy sobie, że znaleźliśmy jeszcze 2 wpisy danych dotyczące tego Mercedesa, oferujące następujące informacje:
- Dokument #1:
- Kraj wpisu: Szwecja
- Przebieg: 187 000 km
- Data rejestracji: 20 października 2022 r.
- Dokument #2:
- Kraj rejestracji: Finlandia
- Data przeglądu technicznego: 7 września 2023 r.
- Przebieg: 105 000 km
- Emisja CO2: [x g/km]

Te informacje tworzą całkiem niezłą historię – musimy je tylko połączyć.
Aby to zrobić, grupujemy typy informacji w sekcjach raportu. Na przykład mamy 3 odczyty licznika przebiegu i daty ich wykonania. Pojawią się one w sekcji “Przebieg” raportu. Tymczasem informacje o przeglądzie technicznym znajdą się w sekcjach “Status prawny” i “Oś czasu” itp.
4. Wykorzystanie modeli statystycznych do generowania spostrzeżeń i wprowadzania poprawek
Tak więc mamy już dane i zostały one przetworzone do wykorzystania w raporcie carVertical. Wciąż jednak pozostaje jeszcze wiele do zrobienia “pod maską” – głównie przy użyciu modeli statystycznych i innych rozwiązań technologicznych w celu naprawienia błędów i wzbogacenia raportu.

Istnieje zbyt wiele zastosowań tych technologii, aby je wszystkie wymienić, ale jako przykład możemy podać, że wykorzystujemy modele statystyczne do dostarczania użytkownikom dodatkowych informacji (np. możemy porównać przebieg naszego przykładowego Mercedesa z innymi samochodami tego samego modelu, w tym samym wieku itp.).

Proces ten działa w obie strony: wykorzystujemy modele statystyczne do wzbogacenia bieżącego raportu i wykorzystujemy dane z bieżącego raportu do wzbogacenia naszych modeli statystycznych.
5. Generowanie raportu
W tym momencie wszystkie zebrane, wyczyszczone, posortowane i wzbogacone informacje są wykorzystywane do wygenerowania raportu carVertical. Wróćmy do naszego Mercedesa, aby zobaczyć ostatni przykład. Oto jak może wyglądać sekcja licznika przebiegu:

Chociaż ten czarny Mercedes może wydawać się atrakcyjny, powyższy wykres powinien skłonić każdego potencjalnego nabywcę do dokładniejszego przemyślenia zakupu!
Z raportu użytkownicy dowiedzą się również o historii samochodu – przybyciu do Szwecji, sprzedaży innemu właścicielowi w Szwecji i ostatecznie dotarciu do Finlandii. Dzięki modelom statystycznym możemy również podać zakres cenowy dla tego modelu samochodu, a także wykres średniego przebiegu (chociaż ten ostatni nie zmieniłby się zbytnio, biorąc pod uwagę cofnięcie przebiegu!) i nie tylko.
Sprawdź swój numer VIN
Unikaj kosztownych problemów, sprawdzając historię pojazdu. Otrzymaj raport błyskawicznie!
Uszkodzenia, odczyty przebiegu i inne informacje: Z jakich źródeł pochodzą poszczególne dane?
Bez omawiania konkretnych baz danych ani źródeł określonych informacji w naszych raportach, możemy przyjrzeć się pewnym ogólnym zasadom dotyczącym tego, skąd mogą pochodzić określone typy danych.
Zanim jednak to zrobimy, ważne jest, aby zrozumieć kilka kwestii:
- Ten sam rodzaj informacji może pochodzić z różnych źródeł. Np. rejestry przebiegu (nawet ten sam wpis) mogą pochodzić z wizyt serwisowych, rejestrów policyjnych lub innych źródeł.
- Występuje również duża różnorodność między krajami. Te same rodzaje instytucji mogą pełnić różne role w systemach prowadzenia dokumentacji w zależności od kraju.
Gdzie zatem można znaleźć te zapisy o uszkodzeniach, odczyty licznika i inne szczegóły?

carVertical posiada certyfikat ISO/IEC 27001:2017
Jako firma zajmująca się przetwarzaniem dużej ilości danych, bardzo poważnie podchodzimy do kwestii bezpieczeństwa. Aby udowodnić nasze zaangażowanie, carVertical uzyskał certyfikat ISO/IEC 27001:2017 - globalny standard bezpieczeństwa informacji.
Co to oznacza?
Aby otrzymać certyfikat ISO/IEC 27001:2017, firma musi wdrożyć narzędzia i procedury chroniące wszystkie informacje ustne, pisemne i elektroniczne otrzymywane, wysyłane, tworzone, zarządzane i wykorzystywane przed wszelkimi możliwymi zagrożeniami: zewnętrznymi, wewnętrznymi, zamierzonymi lub przypadkowymi.
Ten certyfikat oznacza, że wdrożyliśmy surowe środki ochrony wszystkich informacji ustnych, pisemnych i elektronicznych przed wszelkimi zagrożeniami – niezależnie od tego, czy są one zewnętrzne, wewnętrzne, przypadkowe czy zamierzone.
Co to oznacza dla użytkownika? Twoje dane osobowe, dane raportów i dane finansowe są chronione przez najwyższej klasy systemy bezpieczeństwa. Chcesz poznać więcej szczegółów? Zapraszamy do zapoznania się z naszą Polityką Bezpieczeństwa Informacji i Systemem Zarządzania Bezpieczeństwem Informacji (ISMS).
Poznaj zespół ds. danych carVertical!

Raport carVertical jest bardzo czytelny i łatwy w odbiorze, ale za tą prostotą kryje się wiele pracy. Nasz Dział ds. danych dobrze to odzwierciedla: carVertical zatrudnia obecnie prawie 200 pracowników, z czego aż 15% z nich pracuje nad danymi.
To znacząca liczba ludzi, którzy mają talent do matematyki!
Dział ten składa się z 4 wyspecjalizowanych zespołów:
- Zespół ds. pozyskiwania danych skupia się na gromadzeniu surowych danych;
- Zespół ds. inżynierii danych odpowiada za budowanie i utrzymywanie naszej infrastruktury danych i potoków danych;
- Zespół ds. inżynierii uczenia maszynowego opracowuje i wdraża modele uczenia maszynowego;
- Zespół ds. analizy danych analizuje dane w celu wyciągania wniosków i wspierania decyzji biznesowych.
Każdy z tych zespołów odgrywa kluczową rolę w tworzeniu raportu carVertical – dosłownie nie moglibyśmy bez nich istnieć!
Często zadawane pytania
Autor:
Tadas Švenčionis
Tadas jest redaktorem naczelnym bloga carVertical. Jako fan motoryzacji i technologii, stara się przedstawić skomplikowane tematy w prosty i wciągający sposób – w końcu co to za historia, której nikt nie rozumie? Tadas spędza wolne dni na czytaniu, graniu i tworzeniu muzyki, o którą nikt nie prosił. Na co dzień mieszka w Wilnie na Litwie.